Hashing이란?
Hash Table을 알기 전에 Hashing의 개념부터 이해해야 합니다.
Hashing이란 임의의 값을 Hash함수를 이용해서 고정된 크기의 값으로 변환시키는 작업을 의미합니다.
Hash함수는 아래와 같은 종류가 있습니다.
- Division Method: 인풋값을 테이블의 크기로 나누어 모듈러 연산을 통한 나머지를 사용. 이때 테이블의 크기는 소수(Prime Number)여야 나머지 비트를 고려하여 효율적으로 해싱할 수 있음.
- Digit Folding: 키의 문자열을 ASCII 코드로 바꾸고 값을 합한 데이터를 테이블 내의 주소로 사용
- Multiplication Method: 키값 K와 0과 1사이의 실수 A, 임의의 수 m을 사용하여 kAmod1의 연산을 통해 kA의 소수점 이하 부분을 m과 곱하여 사용.
- Univeral Hashing: 다수의 해시함수를 만들어 집합 H에 넣어두고, 무작위로 해시함수를 선택해 해시값을 만들어 사용
이를 통해 특정한 value를 배열의 크기에 따른 고유한 인덱스 값으로 변환할 수 있습니다.
HashTable이란?
인풋값을 Key로 사용하여 위의 Hash함수를 통해 인덱스로 변환, 변환한 인덱스의 주소에 Value를 집어넣고 (Key, Value) 형태로 데이터를 저장하는 자료구조입니다. HashTable을 통해 Dict 자료구조를 효율적으로 구현할 수 있습니다.
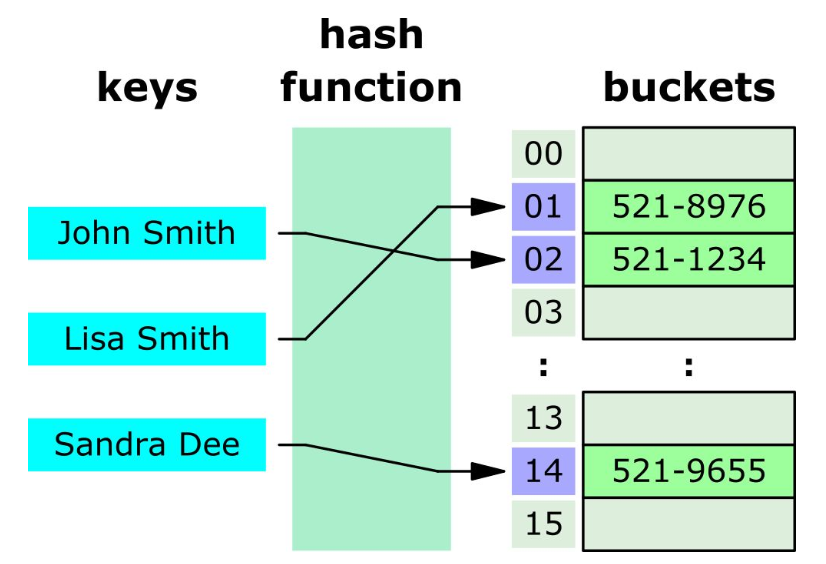
따라서 (John Smith, 521-1234)의 데이터가 있을 때 John Smith는 해시함수를 통과하여 1이라는 값으로 변환되고, bucket의 1번째 인덱스에 (John Smith, 521-1234)가 저장되게 됩니다.
이때 서로 다른 key값이 같은 해시함수를 거친 뒤 같은 index를 나타내는 충돌이 발생할 수 있습니다.
이럴 때 해결하는 방법이 두가지가 있습니다.
1. Separate Chaining
Chaining 기법은 충돌이 발생했을 때 같은 bucket 내에서 추가 메모리(캐시)를 사용하여 연결리스트 형태로 다음 데이터의 주소를 저장하는 방법입니다.
이 방법을 통해 해시 테이블을 크기 확장없이 구현 가능하지만,
원래 해시 테이블의 삽입 및 삭제의 시간복잡도가 O(1)인 반면, Bad case의 경우 최대 Key값의 개수만큼 연결리스트 엔트리가 증가하여 시간복잡도가 O(n)까지 증가할 수 있으며 그에 따라 캐시의 효율성이 감소할 수 있습니다.
이를 해결하는 방법으로는
- 버킷의 크기를 동적으로 늘리거나
- 충돌이 발생하는 연결리스트 엔트리를 Red-Black Tree와 같은 비선형적 계층 구조로 저장함으로써 탐색 시간을 O(logn)까지 줄일 수 있습니다.
2. Open Addressing
Open Addressing 기법은 Chaining처럼 추가 메모리를 사용하지 않고 해시 테이블 내 남아있는 공간을 사용하는 방식입니다. Open Addressing을 구현하는 방법은 3가지가 있습니다.
- Linear Probing: 현재 bucket Index에서 고정값만큼 이동하여 차례대로 검색하여 비어 있는 버킷에 데이터를 저장하는 방식. 이 경우 특정 bucket에 값이 들어올 확률이 높아져 평균 삽입 및 탐색의 시간복잡도가 증가함.
- Quadratic Probing: 해시의 저장순서 폭을 충돌이 발생한 수의 제곱만큼 늘려가는 방식 (첫 충돌 시 1, 그 다음 충돌 시 2^2...만큼 Index 이동). Linear Probing의 군집화 현상을 해결하기 위해 고안됨.
- Double Hashing: 해시된 값을 한번 더 해싱. 해싱을 두번하기 때문에 다른 방법보다 더 많은 연산을 필요로 함.
구현 방법에 따라 Open Addressing의 성능은 달라질 수 있습니다.
성능에 영향을 미치는 큰 요소는 해시 테이블의 Load Factor(사용중인 버킷 / 전체 버킷) 입니다.

위 표는 LF에 따른 평균 탐색 성공 수와 실패 수입니다.
일반적으로 LF는 80%를 넘어가면 효율이 극도로 떨어지기에 그 근처로 제한됩니다.
즉, 가변적인 동적 자료구조는 사이즈를 증가시킬 임계점을 찾을 때 이같은 LF를 활용합니다.
Java의 경우 HashMap을 포함한 Hashtable, ArrayList 등의 LF를 75%로 제한하고 있습니다.
따라서 Open Addressing의 3가지 방법은 LF가 임계치에 다다를수록
linear probing < quadratic probing < double hasing의 순서로 효율적으로 동작함을 볼 수 있습니다.
Separate Chaining과 Open Addressing에 관한 고찰 (with Java & Python)
삭제 연산을 수행할 때, 해시 함수의 리턴값이 같은 Key가 여러개 있는 경우
Chaining 기법은 연결 리스트의 삭제 방법과 동일하게 포인터가 다음 노드를 가르키도록 변경합니다.
하지만 Open Addressing 기법에서 데이터를 삭제하게 되는 경우, 해당 버킷의 공간이 비게 됩니다.
이때 삽입 및 탐색 과정에서 삭제로 인해 비어진 공간을 보고 값이 저장되지 않았다고 판단할 수 있습니다.
이렇게 되면 그 이후 Index에 저장된 pair를 찾을 수 없게 됩니다.
Linear Probing을 예로 들면, n+1 Index의 (key, value)를 삭제했을 때, n+1 index의 bucket이 비게 되고 추후 탐색을 수행할 때 빈 공간을 만나면 더이상 탐색을 지속하지 않아 n+2 Index의 (key, value)를 찾을 수 없게 될 수 있습니다.
이러한 문제는 삭제한 공간에 Null과 같은 임의의 값을 저장하여 그 값을 만날 경우 탐색을 계속하게 함으로써 해결할 수 있습니다.
하지만, 그렇게 되면 쓰지 않는 bucket 공간을 Null이 차지하는 메모리 누수가 발생하게 되어 비효율적입니다.
C와 같은 Low-level 언어가 아니면 자동적으로 garbage collection이 수행되어 도달 가능성이 없는 객체를 메모리에서 삭제하게 되지만, 이또한 비용이 발생합니다.
추가적으로 Chaining의 경우 작동 원리의 특성 상 LF가 증가하여도 성능 저하가 linear하지만 Open Addressing은 LF가 증가함에 따라 성능이 비약적으로 떨어지게 됩니다. (아래 표 참고)
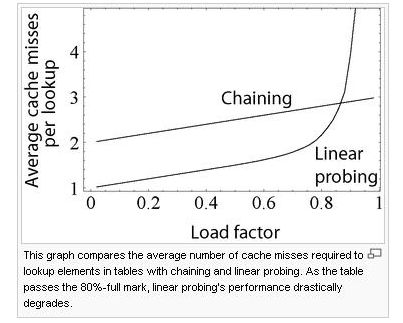
이러한 이유들로 인해 Java의 HashMap에서는 Open Addressing이 아닌 Separate Chaining 방법을 사용하고 있습니다.
Java는 Robust한 언어라 불리기에 메모리 관리의 안전성과 견고성에 초점을 둡니다.
따라서 Separate Chaning 기법이 Linked-list의 메소드에 synchronized 키워드를 선언하여 동기적으로 구현하기 비교적 쉽기 때문에, 자바의 멀티 쓰레드 환경에 맞는 thread-safe한 기법인 Separate Chaining을 선택한 것으로 보입니다.
반면 파이썬의 경우에는 HashTable로 구현한 Dict 클래스에서 충돌이 발생할 때 Open Addressing 방법을 사용합니다.
기본적으로 싱글스레드로 동작하고, 간결하고 빠른 개발속도를 추구하는 파이썬의 특성에 기인한 것으로 보입니다.
위에서 Java의 HashMap 등의 자료구조는 LF를 75%로 한다고 언급했는데, Python의 dict 자료형의 경우 LF를 66%로 제한하고, 이 이상으로 데이터가 차면 더 큰 크기의 해시 테이블을 새로 생성한 뒤 기존 데이터를 새로운 해시 테이블로 옮기는 과정을 수행합니다. 옮기는 과정을 제외하면, 위의 표에서 볼 수 있듯이 탐색 속도는 0.66의 Load Factor 아래에서 Chaining보다 더욱 빠른 성능을 낼 수 있습니다.
또한 파이썬의 Dict는 Open Addressing 중에서도 Pertubation Shift Probing이라는 고유의 방법을 사용합니다.

위와 같은 수식을 통해 더 효율적으로 해시 충돌을 해결하였습니다.
python github 공식문서에서 더 디테일한 내용을 찾을 수 있습니다.
https://github.com/python/cpython/blob/v3.9.1/Objects/dictobject.c#L133
GitHub - python/cpython: The Python programming language
The Python programming language. Contribute to python/cpython development by creating an account on GitHub.
github.com
추가) HashTable / HashMap / ConcurrentHashMap
Map을 구현할 때, Java에선 HashTable, HashMap, ConcurrentHashMap 세가지 방법으로 구현할 수 있습니다.
- HashTable은 데이터의 연산 메소드가 synchronized하기에 멀티 쓰레드 환경에서 사용할 수 있습니다. 메소드를 호출하기 전에 쓰레드 간 동기화 block을 걸기 때문에, thread-safe하다고 할 수 있습니다. 속도 면에서 느리다는 단점이 있습니다.
- HashMap은 HashTable 이후 나온 클래스로 메소드가 synchronize 하지 않습니다. 따라서 thread-safe 하지 않아 싱글 쓰레드에서 사용해야 하고 데이터를 탐색하는 속도는 더 빠르지만 안전성, 신뢰성이 떨어집니다.
- ConcurrentHashMap 클래스는 HashMap의 동기화 이슈를 해결하기 위해 고안되었는데, 동기화 처리를 할 때 어떤 엔트리를 조작하는 경우에 해당 엔트리에 대해서만 block을 겁니다. 즉, 쓰레드 간 락을 거는 HashTable과 달리 엔트리 아이템 별로 block을 걸기에 thread-safe하여 멀티 쓰레드에서 동작하면서도 HashTable보다 성능을 향상시켰습니다.
HashTable 예제
https://www.acmicpc.net/problem/17219
17219번: 비밀번호 찾기
첫째 줄에 저장된 사이트 주소의 수 N(1 ≤ N ≤ 100,000)과 비밀번호를 찾으려는 사이트 주소의 수 M(1 ≤ M ≤ 100,000)이 주어진다. 두번째 줄부터 N개의 줄에 걸쳐 각 줄에 사이트 주소와 비밀번
www.acmicpc.net
위 문제는 특정 문자열의 비밀번호를 찾는 문제입니다.
HashTable로 구현한 파이썬의 Dict를 통해 (Key, Value)에 주소와 pw를 저장하면 평균 O(1)의 속도로 원하는 값을 탐색할 수 있습니다.
import sys
n, m = map(int, sys.stdin.readline().split())
hashtable = {}
for i in range(n):
address, pw = map(str, sys.stdin.readline().split())
hashtable[address]=pw
for j in range(m):
search = sys.stdin.readline().rstrip() # 개행문자를 같이 받기때문에 rstrip으로 제거
print(hashtable[search])'CS > Data structure' 카테고리의 다른 글
| [자료구조] AVL tree란? / AVL tree의 연산 방법 및 활용 (0) | 2023.05.23 |
|---|---|
| [자료구조] Graph란? / DFS와 BFS / 활용 및 예제 (백준 1260) (1) | 2023.03.21 |
| [자료구조] Heap과 Priority Queue란? / 활용 및 예제 (백준 11279) (0) | 2023.03.10 |
| [자료구조] Tree란? / 활용 및 예제 (백준 1068) (0) | 2023.03.08 |
| [자료구조] Queue란? / 활용 및 예제 (백준 12873) (0) | 2023.03.06 |
