[운영체제] 11. multi-cpu-scheduling
Reference - Operating Systems: Three Easy Pieces

https://pages.cs.wisc.edu/~remzi/OSTEP/
Operating Systems: Three Easy Pieces
Blog: Why Textbooks Should Be Free Quick: Free Book Chapters - Hardcover - Softcover (Lulu) - Softcover (Amazon) - Buy PDF - EU (Lulu) - Buy in India - Buy Stuff - Donate - For Teachers - Homework - Projects - News - Acknowledgements - Other Books Welcome
pages.cs.wisc.edu
Multiprocessor
개념 정리
CPU : 컴퓨터의 뇌 역할을 하는 하드웨어
Processor : 프로그램 명령을 수행하기 위한 논리회로
Core : CPU(processor)의 구성 요소로, 레지스터 집합으로 이루어진 프로그램의 명령을 읽고 수행하는 독립적인 장치.
(hardware)Thread : 물리적으로 동시에 프로세스를 실행할 수 있는 공간. (ex. 4코어 8스레드 - 코어는 4개지만 실행하는 프로세스 수는 8개)
Concurrency : 프로세스가 동시에 실행되는 것처럼 보임 <-> Parallelism : 물리적 시간동안 동시에 실행
Types of Parallelism
Data Parallelism : 나누어진 데이터에 대한 같은 연산을 여러 코어가 동시에 수행 (ex. 1부터 10은 코어 1이 더하고, 10부터 20은 코어 2가 더하고, ...)
Task Parallelism : 같은 데이터로 다른 연산을 동시에 수행 (코어 1이 덧셈을 하고, 코어 2가 곱셈을 하고, ...)
실제로는 두개를 섞은 Hybrid parallelism을 사용한다.
Amdahl's Law
성능 개선 시, 병렬처리 비용 대비 최대 얼마정도의 performance를 뽑을지 예측하는 law.
Multiprocessor Scheduling: Background
CPU를 더하는 것이 성능 향상을 보장하지 않는다.
왜? -> Cache Coherence(캐시 일관성) and Cache Affinity(캐시 선호도) 때문.
Cache coherence
데이터를 메모리에서 불러오는 것은 오랜 시간이 걸린다.
따라서 컴퓨터는 자주 쓰는 데이터를 CPU 옆 캐시메모리에 저장해두고 빠르게 불러오게끔 설계되어 있다.
캐시에 저장될 데이터는 Locality로 결정되는데, Temporal Locality(최근 사용한 데이터가 다시 사용될 확률이 높다)와 Spatial Locality(데이터가 사용되면 그 근처 데이터도 사용될 확률이 높다) 두 종류가 있다. 참고로 알아두자.

메모리는 하나인데 프로세서가 여러개가 되면, 캐시도 마찬가지로 늘어난다.
이때, CPU는 연산 시 return 값을 메모리에 바로 넣지 않고 cache에 넣어둔다. 메모리는 느리기 때문에 성능 효율성을 고려한 것이다. 이렇게 메모리에 적용되기까지 시간이 지연되는 것을 delayed write라 한다.
이때, A 데이터를 CPU 1에서 +1한뒤 delayed write로 인해 메모리에 입력되기전에 CPU 2가 가져가면 연산이 중복 처리될 것이다. 이러한 문제를 cache coherence, 캐시 일관성이라 한다.
Solution은 Bus snooping이라는 방법이다. CPU가 cache data가 update되는 것을 모니터링하다가 다른 캐시에서 접근을 하면, 값 변경을 무효화하거나 값을 업데이트 하는 등의 적절한 처리를 제공한다. Bus snooping은 하드웨어에 의해 제공된다. 하지만 모든 프로세서에 브로드캐스트가 발생하여 overhead가 크므로 주의해야 한다.
Don't forget synchronization
캐시의 일관성을 제공하기 위해 mutual exclusion 등을 사용할 수 있다.
int List_Pop() {
Node_t *tmp = head; // remember old head ...
int value = head->value; // ... and its value
head = head->next; // advance head to next pointer
free(tmp); // free old head
return value; // return value at head
}다음과 같은 함수를 두 CPU에서 동시에 실행한다고 가정하자.
동일한 메모리에 중복 free가 발생하여 process crush가 발생할 것이다.
이때 아래처럼 lock을 걸어 mutual exclusion을 구현하면 해결할 수 있다.
pthread_mutex_t m;
int List_Pop() {
lock(&m) // lock
Node_t *tmp = head; // remember old head ...
int value = head->value; // ... and its value
head = head->next; // advance head to next pointer
free(tmp); // free old head
unlock(&m) //unlock
return value; // return value at head
}참고로, 이렇게 lock을 거는것은 multiprocessing을 못하게 하기 때문에 성능 저하가 발생할 수 있다.
따라서 가능한 CAS 등의 hardware instruction을 사용하면 좋다.
Cache Affinity
캐시 선호도는 프로그램이 실행할 때 사용했던 데이터들은 캐시에 몰려있으므로, 프로그램을 스케줄링할 때 가능한 같은 CPU에서 실행되도록 하는 것이 캐시에 따른 성능 측면에서 좋다는 것이다.
Multiprocessor Scheduling: Algorithms
multiprocesor에서 스케줄링을 사용하는 두 방법으로 SQMS와 MQMS가 있다.
Single Queue Multiprocessor Scheduling (SQMS)
SQMS는 싱글 프로세서에서 쓰던 스케줄러를 그대로 사용하는 것이다.
즉, 하나의 큐에 작업들을 넣어 처리한다. 간단하다는 장점이 있지만, 단점도 존재한다.
1. Lack of scalability: Lock을 사용하면 성능이 크게 저하될 수 있다 - 확장성 부족
2. Cache affinity: time slice마다 각 cpu에 다른 job이 들어오면 cache affinity는 최악이 된다.
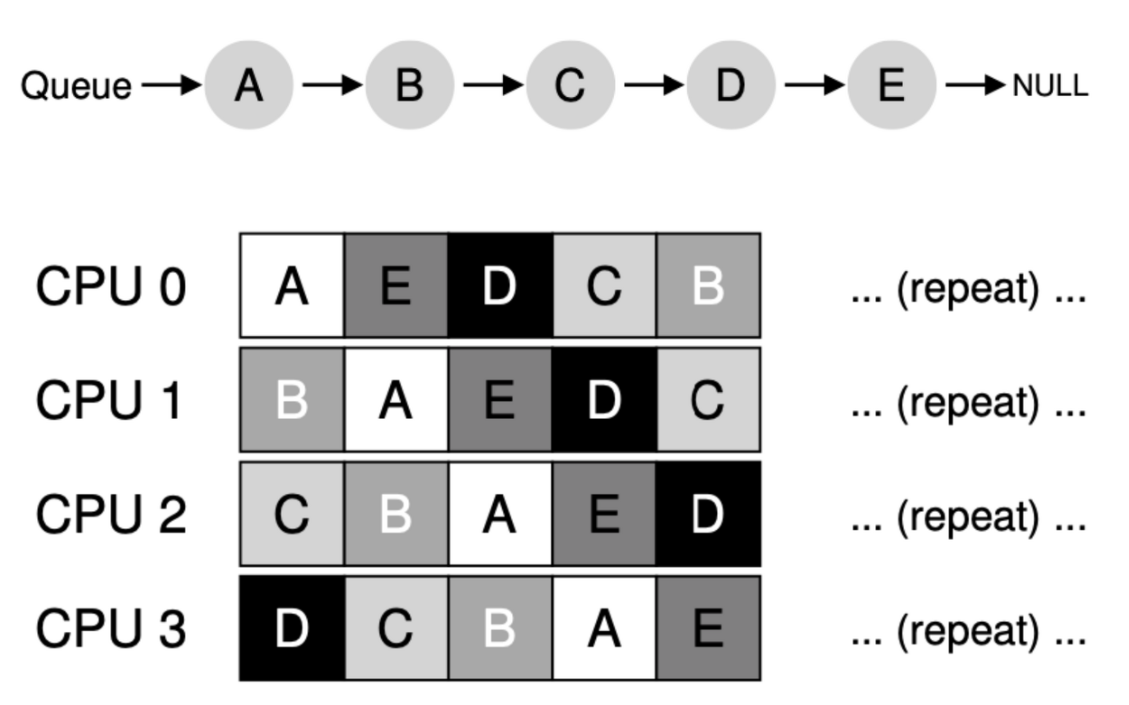
이를 해결하기 위해 아래처럼 최대한 한 cpu에 같은 job을 넣는 매커니즘을 사용하지만, 여전히 특정 프로세스는 캐시 친화도가 안좋을 수 있다. (아래의 경우 E process)

Multi Queue Multiprocessor Scheduling (MQMS)
여러개의 큐를 사용하여 SQMS의 문제점을 보완하였다.

CPU는 각각 하나 또는 그 이상의 큐를 가지며 각각의 큐는 RR과 같은 특정한 스케줄링 방법을 사용한다.
작업이 시스템에 들어오면, 정확히 하나의 큐에 배치된다.
Lock에 따른 scalability 이슈가 없고, cache affinity 측면도 더 좋다.
하지만 MQMS도 문제가 있다. 위의 경우 큐에 있는 작업 수가 같고 프로세스가 끝나지 않아서 load balance 측면에서 효율이 좋지만, 큐마다 작업 수가 다르거나 특정 프로세스가 먼저 끝나면 각각의 cpu가 가지는 job이 imbalance하게 된다. (Load imbalance issue)
이런 문제는 migration, 즉 프로세스가 많은 CPU의 프로세스를 프로세스가 적은 CPU로 옮겨주면 된다.
만약 프로세스가 홀수개여서 프로세스를 옮길 시 또 balance가 맞지 않는다면 지속적으로 프로세스를 한번씩 옮겨주면 된다. 이렇게 프로세스가 적은 큐에서 프로세스를 가져오는 것을 work stealing이라 한다. 하지만 이 경우 load balancing은 되지만 프로세스를 이동하는 work stealing에 따른 overhead 이슈가 생긴다. 이는 아직 해결못한 숙제이다.