Reference - Operating Systems: Three Easy Pieces

https://pages.cs.wisc.edu/~remzi/OSTEP/
Operating Systems: Three Easy Pieces
Blog: Why Textbooks Should Be Free Quick: Free Book Chapters - Hardcover - Softcover (Lulu) - Softcover (Amazon) - Buy PDF - EU (Lulu) - Buy in India - Buy Stuff - Donate - For Teachers - Homework - Projects - News - Acknowledgements - Other Books Welcome
pages.cs.wisc.edu
LFS
Log-structed File System
- 최근에 나온 LFS를 안쓰고 journaling을 쓰는 이유 : File system의 경우 안전성이 제일 중요한데, journaling이 안정적인게 검증이 되었기 때문이다. 안드로이드에선 LFS를 쓰기 시작했고, 서서히 바뀌고 있는 추세다.
LFS는 전체 저장공간을 journal처럼 관리한다.
즉 모든 파일과 디렉토리가 이전처럼 정해진 위치에 inode, superblock 등을 둔게 아니라,
디스크에 write할 때 업데이트를 메모리의 segment에 버퍼링해놓고 한번에, 항상 새로운 위치에 append시킨다.
이 방법의 장점은 consistent update problem이 없고 double writes가 없으며 좋은 write performance를 제공한다. -> disks are optimized for sequential I/O operations.
단점은 read할 때 random read로 인해 문제가 있다. 이는 캐싱을 통해 보완한다.
과정
먼저 디스크 주소 A0에 데이터를 쓴다. 메타데이터(inode)도 연속적으로 쓴다. inode가 가리키는 파일의 첫번째 block은 바로 앞에 있다. 이때 single block을 두개 순차적으로 write하면, 디스크가 도는 동안 시간이 지났다면, 디스크가 한바퀴를 돌아 이전 block의 다음block에 도달할 때까지 시간이 오래 걸린다.
이 경우 메모리에서 버퍼링을 통해 한꺼번에 쓰면 된다. 이러한 write buffer 단위를 segment라고 부른다.
만약 파일이 4개의 블락을 필요로 한다면, 4개 block뒤에 inode를 작성한다.
디스크 속도가 빨라질수록 버퍼 크기는 커져야한다. 버퍼(segment)는 얼마를 가져야 할까?
- 버퍼 크기 증명 과정
D MB를 디스크에 쓰는데 걸리는 시간은 Twrite라 가정하자.
Twrite = Tp (=seek time+rotational latency) + D/R(최대대역폭)
이때 버퍼당 유효 쓰기 속도 R_effect를 F * R로 하자. 이는 D를 Tw로 나눈 값과 같다.
F는 하이퍼파라미터로, 만약 F가 0.9면 최대대역폭의 90퍼를 쓸 때의 버퍼 사이즈를 유추하는 것이다.
해당 예시로 D를 구해보자. Tp=10ms, 대역폭 R=100MB/s로 가정한다.
F*R = D/Tw = D/(Tp+D/R)
이를 전개하면 D = F/(1-F)*R*T가 된다. 계산하면, D = 9MB다. 따라서 segment size는 적어도 9MB가 되야한다.
즉 이를 통해 적절한 버퍼 사이즈 D를 유추할 수 있다.
- LFS의 문제점
이전에 파일이나 디렉토리를 여는 과정은 루트의 inode가 2번으로 약속했고, inode table로 간다음 traverse를 통해 최종적으로 읽고자하는 파일의 inode를 찾아서 그 inode를 통해 파일을 찾았다.
반면 LFS는 inode가 쓰여지는 위치가 마음대로다. 루트의 inode가 어디에 쓰일지를 모른다는 것이다.
그래서 Inode Map만든다. inode map은 inode 번호를 받아 inode 주소를 생성해낸다.
LFS는 항상 새로운 위치에 데이터를 쓰기에, inode가 업데이트 될 때마다 inode map도 업데이트해줘야한다.
이렇게하면 데이터를 기록하고, inode가 추가될때마다 inode map를 찾아 기록해야하기 때문에 seek overhead를 줄이려고했는데 또 inode map을 찾는 seek overhead가 생긴다. 그래서 inode map은 inode 뒤에 append한다.
inode를 찾기위해 inode를 가리키는 inodemap을 만들었는데 이걸 왜 inode뒤에 append하는가? 그럼 inode를 찾는 inode map도 똑같이 흩어지는 것 아닌가?
그 해답은 checkpoint region에 있다. 디스크의 특정 부분에 inode map을 찾는 checkpoint region을 둔다. inodemap과 비슷해보이지만, multi level page table과 마찬가지로 pointer만 넣는 것이 사이즈가 적기에 효율적이다. 즉checkpoint region에 쓰는 overhead를 줄이자는 것이다. checkpoint region은 사이즈가 작기때문에 매번 업데이트하지 않고, 약 30초마다 업데이트한다. 이방법도 물론 overhead가 있지만, 그 영향이 기존 방법에 비해 상대적으로 덜하다.
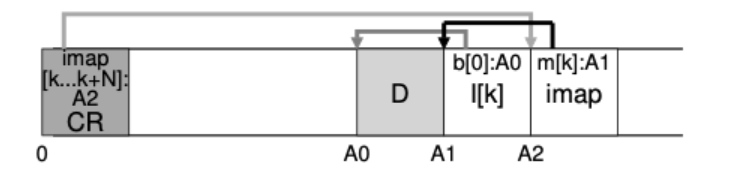
- LFS가 파일을 읽는 과정
제일 처음 보는것은 1.c heckpoint region을 봐야한다. CR을 메모리에 캐시하고, 이를 통해 빠르게 2. k의 inodemap을 찾아가고, 3. inodemap에서 k inode를 찾아가고, 4. k inode에서 데이터 주소를 찾는다. 이러한 과정으로 인해 그 전 방법(journaling)보다 read 과정이 두번이 더 추가된다. write는 효율적인데 read는 더 비효율적이다.
dram 용량이 커짐에 따라 checkpoint region과 inodemap을 dram에 캐싱할 수 있기 때문에 write에 비중을 더 두는게 좋다는 가정이지만, 일부는 맞고 일부는 틀렸다고 한다.
directory도 파일이니까 append only, 쓰이는 방식은 똑같다. inode 위치가 변경되면 inode map만 업데이트해서 디렉토리 트리구조를 유지한다.
- Garbage Collection
SSD는 구조적 문제로 가비지 컬렉션이 발생했지만, LFS는 쓸 수 있음에도 데이터를 기록(업데이트)하는 skim이 항상 새로운 위치에 append하는 방식이라 동일한 문제가 발생한다. invalid 공간이 회수되지 않으면 디스크가 언젠가 쓰레기값으로 꽉찰것이다. append를 하면 append된 새로운 데이터와 inode block이 생기며 기존 데이터는 사용하지만 기존 inode가 garbage가 된다. 하지만 이 inode garbage는 garbage history를 통해 recovery에 쓰일 수 있다. 이러한 시스템을 versioning file system이라 한다. 하지만 디스크 자원은 한정적이기에, LFS는 파일의 최신 버전만 유지한다. 오래된 데이터를 삭제하는 작업을 garbage collection이라 한다. segment 내에서 살아있는 애는 다른 디스크 블럭으로 옮기고, victim으로 선정된 segment를 free시킨다. FTL과 동일한 컨셉이다. 이 경우 extra IO가 발생하기 때문에 퍼포먼스가 좀 떨어진다.
garbage collection을 위해 4개의 block을 segment로 보자. victim을 구하기 위해 segment 내 block이 얼마나 살아있고 얼마나 죽은지 확인해야 한다. 각 segment의 head에는 Segment summary block이 있다. segment summary는 segment의 상태를 보여주지만, 뭐가 살아있는진 보여주지 않는다. 이를 확인하기 위해 checkpoint region->inodemap->inode가 최근 데이터를 가리키고있기 때문에 이를 통한 summary block이 나를 가리키고 있으면 나는 liveness하다고 할 수 있다. 다른 애를 가리키면 값이 변경된, 죽은 데이터다.
가비지 컬렉션(clean)은 언제 해야할까?
디스크가 꽉차거나, 시간이 날때 하거나, 주기적으로 하거나. -> 충전이 되어 있고, 자는 시간일 때 수행
어떤 블락을 clean할까?
hot segment(빈번)의 경우, 빈번한 놈은 업데이트로 데이터를 자주 덮어쓰므로 한번에 처리하는게 효율적이다. 따라서 cold segment를 먼저 clean한다.
- crash recovery and the log
checkpoint가 head segment를 포인팅하고, head segment는 그다음 segment를 포인팅한다. fail을 알아차리기 쉽다.
그럼 checkpoint region을 writing하는 중에 fail이 나면 어떡할까? checkpoint는 overwrite가 가능한데, 그래서 문제가 크다.
이를 해결하기 위한 case 1은 따라서 checkpoint 2개를 만들어놓고 번갈아서 쓴다. update 중에 failure가 나면 다른 이전 checkpoint로 돌아간다. case 2는 segment를 쓸 때 발생하는 충돌인데, 체크포인트를 30초마다 flush하는데 29초 후 failure가 나면 29초 간의 segment는 날라갈 수 있다. LFS는 그렇지 않고 기록할때마다 각 segment가 다음 segment를 포인팅해서 마지막까지 chaining을 해서 end log인 TxE가 문제있는 block을 확인하면 복구할 수 있을 것이다.
LFS가 갑자기 다시 사용되는 이유는 급속도로 발전한 SSD의 특징 때문인데,
디스크는 header로 움직이기에 random read의 영향이 컸지만 SSD는 그렇지 않기 때문에 각광받고 있다.
'CS > 운영체제' 카테고리의 다른 글
| [운영체제] 27. FSCK and Journaling (2) | 2023.12.10 |
|---|---|
| [운영체제] 26. Fast file system (1) | 2023.12.10 |
| [운영체제] 25. File system Implementation (1) | 2023.12.10 |
| [운영체제] 24. File and Directory (0) | 2023.12.09 |
| [운영체제] 23. Flash-based SSD (0) | 2023.12.08 |
